
Divide and Conquer
[책] 리눅스 커널 내부구조 본문
1. Unix System V 기준의 process scheduling 기법 조사
1.1. 기본 scheduling 기법 조사
1.1.1. Process priority 조정 방법 등
1.2. Fair Share Scheduling 기법 조사
1.2.1. FSS 목적, scheduling 방법 등
2. Linux version 2.6 이후의 scheduling 기법
2.1. Linux scheduling 기법의 overall architecture & mechanism
2.2. Linux scheduling에 사용되는 data structure
2.3. CFS(Completely Fair Scheduling) 기법
2.3.1. Nice value → priority → weight mapping 방법
2.3.2. Nice value to weight mapping의 의미
2.3.3. Time slice와 CPU proportion의 의미
2.3.4. Weight 기반 CPU proportion 계산 방법
2.4. 최근 Linux의 CFS를 대체한 scheduling 기법
2.4.1. New scheduling 기법 명칭 및 개요, 특성 등운영체제는 컴퓨터에 있는 자원을 관리하며, 일반 사용자들이 컴퓨터를 사용할 수 있도록 지원
운영체제는 CPU, 메모리, 디스크라는 3개의 자원를 관리
초기 상태
각 자원은 아무도 사용하지 않은 상태(처음 운영체제를 설치한 상태 등)
사용자가 문서 편집, 프로그램 작성 등의 작업을 수행하면, 이를 위해 필요한 자원을 운영체제가 제공해 줌
만약 사용자가 프로그램 하나를 작성한다고 하면
운영체제는 디스크의 일부 공간을 할당 받음 (일반적으로 디스크 블록이라고 하는 4KB 크기의 공간을 할당 받음)
여기에 파일을 저장함
파일의 속성 정보를 저장하기 위한 공간도 디스크에 할당함 (이 공간이 아이노드)
아이노드와 파일의 내용이 들어 있는 디스크 블록을 연결함
운영체제는 디스크에서 디스크블록을 할당 받아서, 여기에 파일 내용을 기록하고
아이노드를 할당받아 여기에 파일 속성정보를 기록
마지막으로 파일 이름과 아이노드와 디스크 블록을 연결컴파일 이후 에는 바이너리 파일이 만들어 지는데
이 바이너리 파일을 수행하면 그 결과 테스크task라는 새로운 객체가 생성이 됨
(바이너리 파일이 테스크로 수행되기 위해서는, 파일을 구성하는 내용이 메모리로 load되어야 함)
즉, CPU는 디스크를 직접 접근할 수 없으며, 디스크의 내용이 메모리로 적재되어야 함
새로운 태스크는 메모리의 일부 공간인 페이지 프레임을 할당 받아 실행 이미지를 load함
(각 테스크는 세그먼트 테이블과 페이지 테이블을 이용해 할당된 페이지 프레임을 관리)
이 객체는 수행 중인 프로그램으로 정의되고,
기존에 존재하던 태스크들과 서로 경쟁하며 CPU를 사용하려 함
운영체제는 CPU 자원을 모든 테스크들에게 공편하게 나누어 주려고 함
대표적인 방법이 라운드 로빈이라는 방식
라운드 로빈 방식
한 태스크가 정해진 시간동안 CPU를 사용하고, 그 시간이 지나면 다음 태스크가 CPU를 사용... 반복
모든 테스크들에게 적용이 되는 스케줄링 방식
리눅스는 유닉스 계열의 운영체제
유닉스도 운영체제...
유닉스 계열이라는 의미는 운영체제가 SUS(Single UNIX Specification)을 따른다는 의미
IEEE가 정의한 POSIX(Portable Operating Sustem Interface) 표준을 따르는 운영체제를 유닉스 계열 운영체제라고 함
기존의 운영체제와 달리 대부분의 소스코드를 고급언어인 C로 작성
BSD, System V, Solaris, AIX, ... 등 유닉스 계열의 운영체제를 발표
운영체제는 크게 BSD 계열과 System V/III 계열로 나뉨
| BSD | System V/III |
| TCP/IP 통신 프로토콜이 최초로 구현 | IPC(Inter Process Comm) 등 ... |
Ch 2. 리눅스 커널의 구조
운영체제가 관리해야 할 자원은 크게 Physical resource와 Abstract resource가 있다
물리적인 자원은 CPU, 메모리, 디스크, 터미널, 네트워크 등 시스템을 구성하고 있는 요소들과 주변장치 등이 있다
추상적인 자원은 CPU를 추상화한 테스크, 메모리 추상화한 세그먼트와 페이지, 디스크를 추상화한 파일, 네트워크를 추상화한 통신 프로토콜과 패킷 등이 있다
<리눅스 커널 내부의 5가지 부분>
1. CPU라는 물리적인 자원을 테스크라는 추상적인 자원으로 제공하는 것이 테스크 관리자
2. 메모리를 세그먼트나 페이지라는 개념으로 제공하는 메모리 관리자
3. 디스크를 파일 개념으로 제공하는 파일시스템
4. 네트워크 장치를 소켓이라는 개념으로 제공하는 네트워크 관리자
5. 각종 장치들을 디바이스 드라이버를 통해 일관되게 접근하도록 해주는 디바이스 드라이버 관리자
1. 테스크 관리자
테스크의 생성, 실행, 상태 전이, 스케줄링, 시그널 처리, 프로세스 간 통신 등의 서비스를 제공
2. 메모리 관리자
물리/가상 메모리 관리, 세그멘테이션, 페이징, 페이지 부재 결함 처리 등
3. 파일시스팀
파일의 생성, 접근 제어, 아이노드 관리, 디렉터리 관리, 수퍼블록 관리 등
4. 네트워크 관리자
소켓 인터페이스, TCP/IP 같은 통신 프로토콜 등의 서비스 제공
5. 디바이스 드라이버 관리자
디스크나 터미널, CD, 네트워크 카드 등과 같은 주변장치를 구동하는 드라이버들로 구성
운영체제는 무엇을 위해 이렇게 자원을 관리하는가?
> 사용자에게 서비스를 제공하기 위함
> 서비스는 시스템콜의 호출을 의미
= 운영체제는 시스템 호출을 통해 테스크가 자원을 사용할 수 있게 해주는 자원관리자
Ch 3. 프로세스와 쓰레드 그리고 테스크
| 테스크 | 쓰레드 | 프로세스 |
| 자원 소유권의 단위 | 수행의 단위 | 동작중인 프로그램 프로그램은 디스크에 저장되어 있는 실행 가능한 형태의 파일 실행 가능한 형태의 파일은 컴파일 과정을 거쳐 얻어진 바이너리 기계 명령어와 수행에 필요한 자료들의 집합으로 구성 |
test.c라는 파일을 작성해 간단한 프로그램을 만들었음
gcc를 이용해 컴파일하여 test라는 이름의 바이너리 프로그램을 생성(elf 실행 파일)
test 프로그램을 수행
> test 라는 프로세스가 확인
> 실행파일 자체는 그저 디스크에 저장되어 있는 파일 형태
> 커널로부터 CPU 등의 자원을 할당 받을 수 있는 객체가 되어야 함
> 이 동적인 객체가 프로세스 = 동작 중인 프로그램
프로세스는 커널로부터 할당받은 자신만의 자원을 가지고,
CPU가 기계어 명령들을 실행함에 따라 끊임없이 변화하는 동적인 존재
스케줄링
커널이 시스템에 존재하는 여러개의 프로세스 중 CPU라는 자원을 어느 프로세스에게 할당해 줄 것인가 결정하는 작업
프로세스가 수행되기 위해서는 커널로부터 자원을 할당받아야 함
각각의 프로세스별로 주어지는 가상 공간 역시 자원
32bit의 CPU의 경우 운영체제는 각 프로세스에게 총 4GB 크기의 가상 공간을 할당
리눅스에서는 이 공간 중 0~3 GB를 사용자 공간으로 사용하고, 3~4GB를 커널 공간으로 사용
64bit의 경우 2^64=16EB 크기의 가상 공간 중 약 128TB 공간을 사용자 공간으로 사용
===
main() 함수 내에서는 malloc() 함수를 통해 메모리를 동적 할당 받아 포인터 변수로 치환
프로세스는 수행 중에 malloc()과 free() 등의 함수를 사용하여 동적으로 메모리 공간을 할당 받을 수 있다
> 메모리가 할당되는 공간을 힙heap 영역이라고 함
<프로세스는 4개의 영역(리전)으로 구분>

텍스트: 명령, 함수 등으로 구성 / CPU에서 직접 수행되는 명령어(inst.)
데이터: 전역변수 등
힙: 아래에서 위로 자람 / 동적 할당받은 내용
스텍: 위에서 아래 방향으로 자람 / 지역변수와 인자, 함수의 리턴 주소
fork()를 사용하면 프로세스가 새로 생성됨
부모 프로세스의 pid가 10404 -> 자식 프로세스의 pid는 10405
프로세스가 생성되면 주소 공간을 포함하여 모든 자원들이 새로 할당됨
> 부모 프로세스의 변수와 무관하게 됨
쓰레드의 생성이었을 경우
동일한 pid를 갖고, 서로 같은 주소 공간을 공유함
> 한 프로세스에 2개의 쓰레드가 동작함
프로세스나 쓰레드마다 task_struct라는 테스크를 관리하기 위한 자료 구조가 필요함
테스크가 실행되면서 여러 파일을 오픈할 수 있고, 그 결과 파일 디스크립터 fd를 리턴받는다
테스크를 스케줄링하기 위해 필요한 정보인 우선순위, CPU 사용량 등의 정보도 필요하며...
테스크와 관련된 모든 정보를 context라고 한다

테스크는 생성된 뒤, 자기에게 주어진 일을 수행하며
이를 위해 디스크 IO나 락 등 CPU 이외의 자원을 요청하기도 한다
> 자원을 요청했는데 당장 제공해 줄 수 없을 경우, 커널은 이 테스크를 sleep해서 대기하게 한다
> 테스크는 이러한 상태 전이 state transition에 따라 동작하게 된다
일단 테스크가 생성되면 그 테스크는 TASK_RUNNING 상태가 된다
스케줄러는 여러 테스크 중에서 실행시킬 테스크를 선택해 수행시킨다
> 이에 TASK_RUNNING 상태는 TASK_RUNNING(ready)와 TASK_RUNNING(running) 상태로 나뉘어진다
실행 상태에 있는 테스크들은 다음과 같은 상태 전이가 일어날 수 있다
1. 할 일을 다 끝내고 exit()/kill()을 호출하면 TASK_DEAD 상태가 된다
테스크에게 할당되어 있는 자원을 커널에게 대부분 반납
종료된 이유 등을 부모프로세스에게 알리기 위해 유지
추후 부모프로세스가 wait() 등의 함수를 호출하면 상태는 ZOMBIE에서 DEAD로 바뀌고
부모는 자식의 종료 정보를 넘겨 받으며, 자원을 모두 반환 후 종료한다
부모가 자식보다 먼저 종료되면 어떻게 될까?
wait() 함수 등을 호출하기 전에 먼저 종료되는 경우,
부모가 없는 좀비 상태의 자식 테스크의 부모를 init 테스크로 바꾼다
init 테스크가 wait()함수 등을 호출한 후 고아 테스크가 소멸된다
2. running 상태에서 할당된 시간을 모두 사용했거나, 보다 높은 우선순위의 테스크로 인해 ready 상태로 전환되는 경우
리눅스는 여러 테스크들이 CPU를 공평하게 사용할 수 있도록 해주기 위해,
CFS(Completely Fair Scheduling) 기법을 사용한다
3. SIGSTOP, SIGTSTP, SIGTTIN, SIGTTOU 등의 시그널의 받은 테스크는 TASK_STOPPED 상태로 전이된다
추후 SIGCONT 시그널을 받아 다시 TASK_RUNNING(ready) 상태로 전환된다
4. TASK_RUNNING(running) 상태에 있던 테스크가 특정한 event를 기다려야 할 경우
대기상태 TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE로 전이한다
언인터럽티블 상태는 시글널에 반응하지 않는다
대기상태로 전이한 테스크는 event에 따라 특정 큐에 매달려 대기한다
실행중이던 테스크가 대기하게 되면 다시 스케줄러가 호출되며
스케줄러는 준비(TASK_RUNNING(ready)) 상태에 있는 테스크 중 하나를 선택하여
TASK_RUNNING(ready) 상태로 만든다
테스크가 기다로고 있던 이벤트가 발생하면 대기하던 테스크는
준비 TASK_RUNNING(ready) 상태로 전이하며
다른 테스크들과 함께 스케줄링되기 위해 경쟁하게 된다
75페이지
여러개의 테스크들 중에서 다음번 수행시킬 테스크를 선택하여 CPU라는 자원을 할당하는 과정이 스케줄링
리눅스의 테스크는 실시간 테스크와 일반 테스크로 나뉨
리눅스는 140 단계의 우선순위 중, 0~99단계가 실시간 테스크, 100~139까지가 일반테스크가 사용한다
> 실시간 테스크가 항상 일반 테스크보다 우선 실행된다
7-1 런큐와 스케줄링
런 큐(Runqueue)
운영체제가 스케줄링 작업 수행을 위해 관리하는 수행 가능한 상태의 테스크들의 자료구조
운영체제의 구현에 따라 런큐는 한개 ~ 여러개 존재 가능 + 자료구조의 모양이나 관리 방법도 상이
부팅이 완료된 이후, 각 CPU별로 하나씩의 런큐가 유지됨
테스크가 처음 생성되면 init_task를 헤드로 하는 이중 연결 리스트에 삽입된다(이중 연결 테스크를 tasklist라 하겠다)
시스템에 존재하는 모든 테스크들은 전부 tasklist에 연결되어 있다
이중에서 TASK_RUNNING 상태인 테스크는 시스템에 존재하는 런큐 중 하나에 소속된다
다중 CPU 환경에서 런큐가 여러개라면 새로 생성된 테스크는 어느 런큐에 삽입될까?
일반적으로는 새로 생성되는 테스크는 부모 테스크가 존재하던 런큐로 삽입된다
(이는 자식 테스크가 부모 테스크와 같은 CPU에서 수행될 떄 더 높은 cache affinity 캐시 친화력을 얻을 수 있어서다)
대시 상태에서 깨어난 테스크는, 대기 전에 수행되던 CPU의 런큐로 삽입된다(이도 캐시 친화력을 활용하기 위함)

그림에서
wake_up_new_task()는 새로 생성되어, TASK_RUNNING 상태가 된 테스크가 런 큐로 삽입되는 과정이다
wake_up() 함수는 이벤트를 대기하다가 꺠어나서 런 큐로 삽입되는 과정을 보여준다
===
리눅스는 task_struct의 cpus_allowed 필드에 테스크가 수행될 수 있는 CPU의 번호가 들어있고, 이로 삽입될 런큐를 결정
새로 생성된 테스크의 cpus_allowed 필드는 wake_up_new_task()가 수행될 때 부하균등을 고려하여 수정된다
스케줄러가 수행되면 해당 CPU의 런큐에서 다음번 수행시킬 테스크를 골라낸다
이때 어떤 테스크를 선택할 것이냐와 런큐간의 부하가 균등하지 않은 경우 어떻게 할 것인가하는 문제를 고려한다
1. 어떤 테스크를 선택할 것인가?
이를 위해 일반적으로 리눅스는 CFS를 사용한다
실시간 테스크를 위해서는 FIFO, RR, DEADLINE 정책을 사용한다
2. 런큐간의 부하가 균등하지 않은 경우 어떻게 할 것인가?
이를 위해서 리눅스는 부하균긍(load balancing) 기법을 제공한다
load_balance() 함수가 이를 담당하는데
특정 CPU가 많은 작업을 수행해서 매우 바쁜데, 다른 CPU들은 한가하다면
다른 CPU로 테스크를 이주migration 시켜서 시스템의 전반적인 성능 향상을 시도한다
해당 함수는 tick 타이머 인터럽트에 기반하여 주기적으로 호출되거나
특정 CPU의 런큐가 비게 되는 경우
실시간 테스크의 상태 전이에 의해 호출된다
2-1 특정 테스크를 이주하려고 결정했다면 어느 CPU로 이주시킬 것인가 결정이 필요하다
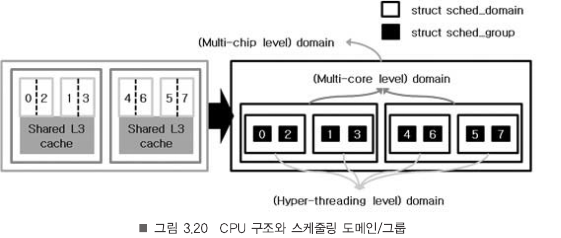
리눅스는 위의 자료구조를 유지한다
좌측에는 하이퍼쓰레딩을 지원하는 듀얼코어칩이 장착되어 있는 시스템 개념적으로 표현한 것이다
리눅스가 부팅 과정을 정상적으로 종료한 뒤에는, 0~7번까지의 8개의 논리적인 CPU가 존재한다고 인식하게 된다
만약 0번 CPU에서 테스크를 이주시키려고 한다 가정하면,
하이퍼쓰레딩으로 인해 논리적으로 존재하는 2번 CPU로 이주하는 것이 이주에 의한 성능 저하가 가장 적다
만약 2번 CPU도 바쁘다면, L3 캐시를 공유하고 있는 CPU1, 3번이 고려 대상이 된다
다음 고려대성은 4, 6, 5, 7 CPU가 된다
그림의 우측에 보이는 것처럼
도메인 안에 도메인 안에 도메인... 그 안에 그룹
그룹:
각 최소 연산 단위(지금의 경우 8개의 논리적인 CPU)
struct sched_group이라는 자료구조를 사용
도메인:
그룹을 하드웨어적인 특성에 따라 분류한 것
레벨별로 struct sched_domain이라는 자료구조 사용
사실 위의 설명은 SMP 구조의 시스템을 위한 리눅스인 경우에만 해당된다
SMP = Symmetric Multi Processor
각 CPU가 동등하기 때문에 테스크가 어느 곳에서든 수행될 수 있다
그러나 NUMA = Non-Uniform Memory Access 구조의 시스템에서는
load_balance() 함수에서 CPU 부하 + 메모리 접근 시간의 차이 등도 고려해야 한다
7-2 실시간 테스크 스케줄링 (FIFO, RR, DEADLINE)
CPU를 어떤 테스크가 사용하도록 해줄 것인가?
어떤 기준에 근거하여 테스크를 골라낼 것인가?
task_struct 구조체는 policy, prio, rt_priority 등의 필드가 존재한다
1. policy 필드
이 테스크가 어떤 스케줄링 정책을 사용하는지?
- 실시간 테스크인지 일반테스크인지
- 실시간 테스크와 일반 테스크는 각각 3개, 총 6개의 스케줄링 정책이 존재한다
- 실시간 테스크에 사용되는 정책: SCHED_FIFO, SCHED_RR, SCHED_DEALINE
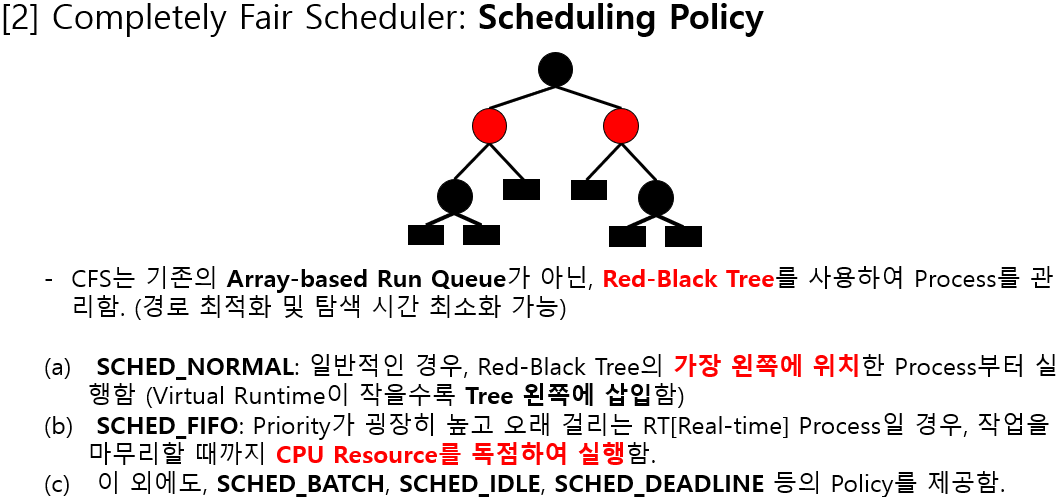
- 일반 테스크에 사용되는 정책: SCHED_NORMAL, SCHED_IDLE, SCHED_BATCH
- SCHED_IDLE: 안 중요한 일을 수행하는 테스크의 CPU 점유를 막기 위해 가장 낮은 우선순위로 스케줄링하는 것
- SCHED_BATCH: 사용자와의 상호작용이 없는 CPU 중심의 일괄작업 테스크를 위함
실시간 테스크란 위에 언급한 정책을 사용하는 테스크를 의미
> 실시간테스크를 생성하는 별도의 함수가 존재하지 않음
> sched_setscheduler() 등의 함수로 테스크의 스케줄링 정책을 셋 중 하나로 바꾸면 실시간 테스크가 되는 것
3. 실시간 테스크는 우선순위 설정을 위해 task_struct 구조체의 rt_priority 필드를 사용한다
0~99의 우선순위를 가질 수 있으며
테스크가 수행을 종료하거나, 스스로 중단, (RR의 경우에만 해당)타임 슬라이스를 다 쓸 때까지 CPU를 사용한다
즉, RR인 경우에는 동일 우선순위를 갖는 테스크가 복수개일 경우, 타임슬라이스 기반으로 스케줄링된다
만약 동일우선순위를 갖는 RR 테스크가 없을 경우 FIFO와 동일하게 동작한다
실시간 정책을 사용하는 테스크는 고정 우선순위를 갖는다
> 우선순위가 높은 테스크가 낮은 테스크보다 먼저 수행된다는 것을 보장하기 위해
===




FIFO나 RR 스케줄링 정책을 사용하는 실시간 테스크는 우선순위가 가장 높은 테스크를 가장 효율적으로 찾기 위해
> tasklist라는 이중 연결 리스트에 연결되어 있으므로, 이 리스트를 이용해 시스템 내의 모든 테스크를 접근할 수 있다
> tasklist를 순서대로 뒤지면서 가장 높은 우선순위의 테스크를 골라내면 된다
> 그러나 이는 테스크의 갯수가 늘어나면 스케줄링에 걸리는 시간도 증가하고(시간복잡도), 스케줄링에 소모되는 시간도 예측할 수 없다(이게 리눅스 커널 버전 2.4의 스케줄러)
리눅스는 이 단점 해결을 위해
FIFO나 RR 정책을 사용하는 테스크들이 가질 수 있는 모든 우선순위 레벨(0~99)을 비트맵으로 표현한다
테스크가 생성되면 비트맵에서 그 테스크의 우선순위에 해당하는 비트를 1로 set하고,
테스크의 우선순위에 해당하는 큐에 삽입한다

스케줄링하는 시점이 되면 커널은 비트맵에서 가장 처음 set 되어 있는 = 가장 높은 순위의 비트를 찾고
그 우선순위 큐에 매달려 있는 테스크를 선택하게 된다
> 고정된 크기의 비트맵에서 최우선 비트를 찾아내는 것은 상수 시간 안에 가능하다
> 고정 시간 내에 스케줄링 작업이 완료된다
===
DEADLINE 정책은 실시간 테스크 스케줄링 기법 중 하나인 EDF = Earliest Deadline First 알고리즘을 구현한 것
커널 버전 3.14 리눅스에 추가되었다
기존의 실시간 테스크 스케줄링 정책은 우선순위 기반 스케줄링 대상을 선정하는데
DEADLINE 정책은 deadline이 가장 가까운 = 가장 급한 테스크를 스케줄링 대상으로 선정한다
ex) 동영상을 재생하는 테스크
끊김 없이 화면 재생을 위해 30fps 디코딩이 필요
= 이 테스크는 1초당 30번씩 해야 하는 일이 있음
= 해야하는 일을 1초에 30회씩 수행
= 해야하는 일은 1초/30 보다 적은 시간 내에 수행될 수 있는 작업량을 갖고 있음
> 해야하는 일은 언제까지 반드시 수행이 완료되어야 한다는 완료시간이 있음을 의미
> 리눅스의 DEADLINE 정책에서는 완료시간을 deadline, 작업량을 runtime, 초당 30회라는 주기성을 period라고 함
정상적인 동작을 위한 조건
테스크의 runtime과 deadline은 ( 현재시간 + runtime < deadline )을 만족해야 함
DEADLINE 정책을 사용하는 테스크들의 runtime 합은 CPU 최대 처리량을 넘을 수 없음
> 새로운 테스크가 해당 정책을 사용하려고 한다면, 기존 테스크들의 runtime과 period를 이용해서
해당 테스크의 성공적인 완료 여부를 확정적deterministic으로 결정할 수 있다는 의미








82페이지. 일반 테스크 스케줄링 CFS
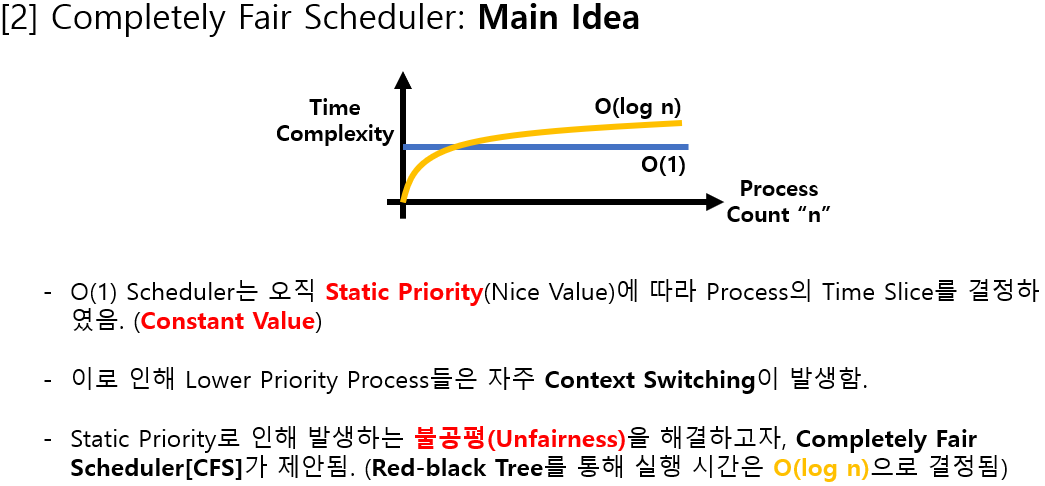
리눅스가 일반 테스크를 위해 사용하고 있는 스케줄링 기법은 CFS(Completely Fair Scheduler)
완벽하게 공평한 스케줄링을 추구한다 > CPU 사용 시간의 공평한 분배를 의미
> A, B 2개의 테스크가 수행 중이라면, A와 B의 CPU 사용 시간이 같아야 한다
그러나, 두 테스크가 번갈아 가며 수행되기 때문에, 임의의 시점에서 두 테스크의 CPU 사용 시간이 항상 같을 수는 없다
이 때문에 정해진 '시간 단위'로 봤을 때, 시스템에 존재하는 테스크들에게 공평한 CPU 시간을 할당하는 것을 목표로 한다
> 런큐에 N개의 테스크가 존재할 경우, 시간단위를 N으로 나누어 N개의 테스크에게 할당해 주면 된다
> 1초를 시간단위라고 한다면, A를 0.5초 수행시키고 B를 수행시켜 1초가 지난 후 둘의 수행 시간을 동일하게 한다
(시간 단위가 너무 길면 테스크의 반응성이 떨어지고, 너무 짧으면 context로 의한 오버헤드가 커질 수 있다)
테스크의 우선순위는 어떻게 반영할 수 있을까?
우선순위가 높은 테스크에게는 가중치를 두어 더 길게 CPU를 사용할 수 있게 해 준다
> A가 우선순위가 높고 B가 작다면, CPU 시간을 2:1로 나누어 분배한다
> 이러면 A가 B보다 많은 시간을 사용할 수 있게 되어, 비교적 일찍 일을 완료할 수 있다
이를 위해 리눅스는 vruntime 개념을 도입했다
각 테스크는 자신만의 vruntime 값을 갖는다
이 값은 스케줄링되어 CPU를 사용하는 경우, 사용시간 + 우선순위를 고려하여 증가된다
> 일반 테스크의 우선순위는 nice() 시스템콜 같은 별도의 지정이 없다면 부모와 동일한 우선순위를 갖게 된다
> 일반 테스크는 사용자 수준에서 볼 때 -20 ~ 0 ~ 19 사이의 우선순위를 갖게 된다
> 이는 커널 내부적으로 (우선순위 + 120) 계산을 거쳐 100~139 사이의 우선순위를 갖게 된다
> 즉 실시간 테스크가 항상 먼저 실행되게 하는 것


스케줄링 대상이 되는 테스크를 어떻게 빨리 골라내는가?
> 가장 작은 vruntime 값을 갖는 테스크가 가장 과거에 CPU를 사용했기 때문에 얘를 선정
> 공평한 스케줄링을 수행하기 위함
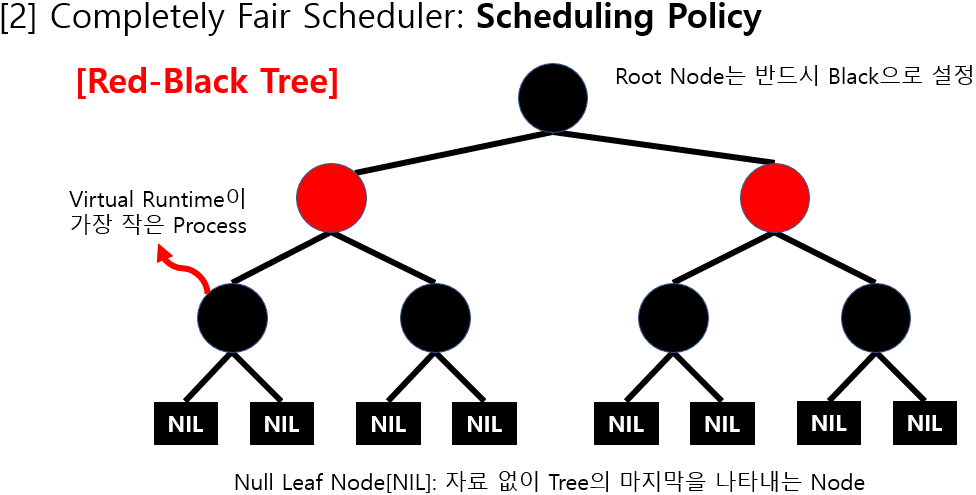
가장 갖은 vruntime값을 갖는 테스크를 빨리 찾아내기 위해서는 RBtree 자료구조를 사용한다
각 테스크는 vruntime 값을 키로 RBtree에 정렬되어 있다
> 이 트리에서 가장 좌측에 위치한 테스크 = vruntime 값이 가장 작은 테스크 = 다음 스케줄링 대상
> 스케줄링된 테스크는 수행될수록 키값이 증가하여 좌측에서 우측으로 이동됨
> 스케줄링이 되지 않은 테스크는 키값이 (상대적으로) 감소되어 좌측으로 이동함
그런데 수행된 시간만큼 테스크의 vruntime값이 증가되며, vruntime값이 가장 작은 테스크가 스케줄링되면
> 자주 스케줄링이 발생되는 문제가 우려될 수 있다
> 각 테스크별로 선점되지 않고, CPU를 사용할 수 있는 시간이(타임 슬라이스) 미리 지정되어 있으며, 타임 슬라이스가 작은 테스크간의 빈번한 스케줄링을 막기 위해 스케줄링간 최소 지연 시간도 고려함

리눅스가 테스크의 우선순위에 따라 각 테스크에게 타임 슬라이스를 어떻게 분배하는데?
리눅스는 시간 단위를 테스크의 우선순위 = 가중치에 기반하여 테스크에게 분배한다
> A와 B라는 2개의 테스크가 있는데, A는 우선순위가 -20이고, B는 우선순위가 0이라면,
> $ A의 타임 슬라이스 = 시간단위 * (88761 / (88761 + 1024) ) $
> $ B_{time\_slice} = {unit\_of\_time} * \frac{ 1024 }{ ( 88761 + 1024 ) } $
이 계산 과정은 sched_sclice() 함수에 구현되어 있다
이때 시간단위는 너무 잦은 스케줄링으로 인한 오버헤드를 최소화하기 위해,
시스템에 존재하는 테스크의 개수를 고려해서 정해지며, 커널의 __sched_period() 함수에서 계산된다
스케줄링 과정 요약
1. 테스크가 처음 생성되면, 시스템에 존재하는 테스크들의 vruntime 값중 가장 작은 값을 자신의 vruntime값으로 갖게 되며, 이를 통해 새로이 생성된 테스크의 빠른 수행을 시도한다.
2. 수행 중인 테스크의 vruntime값은 주기적으로 발생되는 타이머 인터럽트를 통해 우선순위를 고려하여 갱신된다
3. 모든 테스크는 vruntime값을 키고 RBtree에 정렬되어 있으며, 가장 작은 vruntime값을 갖는 테스크가 다음 수행 대상으로 선정된다
4. 단 이때 현재 수행 중인 테스크의 vruntime값이 다른 테스크보다 커지더라도, 해당 테스크의 타임 슬라이스 혹은 스케줄링간 최소 지연시간 내에서는 계속 수행을 보장한다...
아 힘들다 흑흑











-Pabla, Chandandeep Singh, “Completely fair scheduler,” Linux Journal 2009, 184 (2009): 4.
-THE DESIGN OF CFS, https://www.kernel.org/doc/Documentation/scheduler/sched-design-CFS.txt.
'2025 > 개인' 카테고리의 다른 글
| 우리 아빠 여대생 모먼트 (0) | 2025.04.15 |
|---|---|
| 일상 생활에서 활용되는 새로운 시나리오를 현실로 구현하는 로봇 (0) | 2025.03.12 |
| 지금 구매하세요: 쇼핑의 음모 (0) | 2024.05.10 |
| 저출산 해결을 위한 인공 자궁 (0) | 2024.05.10 |
| 멜론 키우기 정리 (0) | 2024.04.01 |

