
Divide and Conquer
[Python] Tesseract를 이용한 OCR 본문
728x90
필수
- tesseract-ocr-w64-setup-v5.0.0-alpha.20210506.exe (64 bit) 를 설치(난 설치 위치 바꿨음)
- https://github.com/tesseract-ocr/tessdata/에서 kor.traineddata 학습된 한글 데이터 다운
D:\보관\기타\설치프로그램\Tesseract-OCR\tessdata(설치 공간)에 kor.traineddata 파일 옮겨
!pip3 install pillow
!pip3 install pytesseract
!pip3 install opencv-python
선택
테서랙트 라이브러리 사용방법 샘플 코드 https://github.com/madmaze/pytesseract
window cmd에서 설치 경로 추가
pytesseract.pytesseract.tesseract_cmd = r'D:\보관\기타\설치프로그램\Tesseract-OCR'
setx PATH "%PATH%;D:\보관\기타\설치프로그램\Tesseract-OCR"
tesseract 쳤을 때 usage 나오면 돼
준비
실험 이미지를 코드가 있는 곳에 옮긴다

코드
import pytesseract as ts
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.image as img
import cv2, sys, os
import numpy as np
print(cv2.__version__)
img_eng = Image.open('test.png')
text_eng = ts.image_to_string(img_eng, lang='eng')
print(text_eng)img_cv = cv2.imread(r'C:/Users/012vi/Desktop/NLP-Korean/Tesseract OCR/test.png')
img_rgb = cv2.cvtColor(img_cv, cv2.COLOR_BGR2RGB)
print(ts.image_to_string(img_rgb))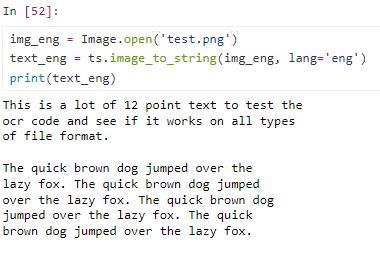

img_kor = Image.open('kor_test.png')
text_kor = ts.image_to_string(img_kor, lang='kor')
print(text_kor)
함수
def OCR(image, lang):
i = Image.open(image)
plt.imshow(i)
plt.title(image)
plt.axis('off')
plt.show()
text = ts.image_to_string(image, lang = lang)
print(text)
print('finish')OCR('kor_test.png', 'kor')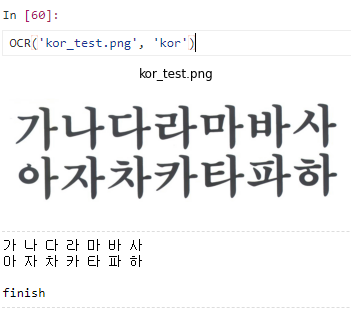
함수 발전
def OCR_Folder():
p = os.getcwd()
path = p.replace('\\', '/')
file_list = os.listdir(path)
img_files = [file for file in file_list if file.endswith('.png')]
print('폴더에 있는 이미지를 출력합니다\n',img_files)
for f in img_files:
OCR(f, 'kor+eng')
print('finish all image processing')
OCR_Folder()
응용
읽고 있던 책을 찍어둔 사진을 OCR로 돌려봤습니다
def OCR(image, lang):
i = Image.open(image)
plt.imshow(i)
plt.title(image)
plt.axis('off')
plt.show()
text = ts.image_to_string(image, lang = lang)
text = text.rstrip()
print(text)
def Folder():
os.chdir("C:/Users/012vi/Desktop/멘탈") # 지정함
p = os.getcwd()
path = p.replace('\\', '/')
file_list = os.listdir(path)
img_files = [file for file in file_list if file.endswith('.png')]
print('폴더에 있는 이미지를 출력합니다\n',img_files)
for f in img_files:
OCR(f, 'kor+eng')
print('finish all image processing')
Folder()
에러 기록
for f in img_files:
image = img.imread(f)
plt.imshow(image)
plt.title(f)
plt.axis("off")
plt.show()Traceback (most recent call last):
File ~\anaconda3\lib\site-packages\IPython\core\interactiveshell.py:3369 in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
Input In [71] in <cell line: 1>
image = img.imread(f) #https://github.com/python-pillow/Pillow/issues/3527
File ~\anaconda3\lib\site-packages\matplotlib\image.py:1560 in imread
with img_open(fname) as image:
File ~\anaconda3\lib\site-packages\PIL\ImageFile.py:112 in __init__
self._open()
File ~\anaconda3\lib\site-packages\PIL\PngImagePlugin.py:676 in _open
raise SyntaxError("not a PNG file")
File <string>
SyntaxError: not a PNG file위의 코드의 에러는 아래와 같이 수정하여 해결함 https://github.com/python-pillow/Pillow/issues/3527
for f in img_files:
image = Image.open(f)
plt.imshow(image)
plt.title(f)
plt.axis("off")
plt.show()
테서랙트 참고 출처
[Python]파이썬 테서랙트(Tesseract OCR) 설치 및 사용방법 총정리 : 이미지에서 문자 텍스트 추출하는
지난 6월 8일 애플 WWDC 2021 전세계 개발자 회의에서 애플은 OCR 기능을 선보였습니다. 강의 영상을 사진으로 찍은 후 바로 문서화 하거나 또는 길거리 간판에서 사진을 찍은 후 사진속의 전화번호
ddolcat.tistory.com
반응형
'성장캐 > 기타' 카테고리의 다른 글
| 행렬 계산기 사이트 (0) | 2021.05.07 |
|---|---|
| [Python] 크롬 북마크 정리 1 (0) | 2021.05.06 |
| 기본 이메일 앱에서 카카오톡 메일 연동 (0) | 2021.05.04 |
| [티스토리] 티스토리에서 PDF 보기 (0) | 2021.05.03 |
| [환경세팅] Anaconda, Jupyter 설치 및 삭제 (0) | 2021.05.02 |
'성장캐/기타' Related Articles
more

Comments