
Divide and Conquer
[Python] 목소리 wav 파형 그리기 본문
728x90

plot을 따로 그리면 보다 자세하게 그려짐
아래는 과정
 |
from scipy.io.wavfile import read import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = [7.50, 3.50] plt.rcParams["figure.autolayout"] = True input_data = read('voice.wav') audio = input_data[1] plt.plot(audio[0:600000]) plt.ylabel("Amplitude") plt.xlabel("Time") plt.show() |
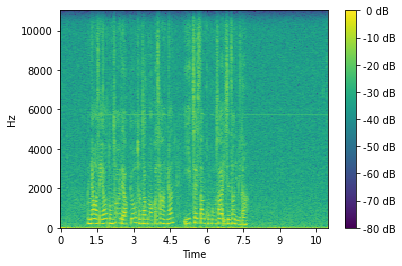 |
import librosa import librosa.display import numpy as np from matplotlib import pyplot as plt audio_path = 'voice.wav' y, sr = librosa.load(audio_path) stft_result = librosa.stft(y, n_fft=4096, win_length = 4096, hop_length=1024) D = np.abs(stft_result) S_dB = librosa.power_to_db(D, ref=np.max) librosa.display.specshow(S_dB, sr=sr, hop_length = 1024, y_axis='linear', x_axis='time', cmap = None) plt.colorbar(format='%2.0f dB') plt.show() |
 |
from scipy.io import wavfile from matplotlib import pyplot as plt import numpy as np # Load the data and calculate the time of each sample samplerate, data = wavfile.read('voice.wav') times = np.arange(len(data))/float(samplerate) # Make the plot # You can tweak the figsize (width, height) in inches plt.figure(figsize=(30, 4)) plt.fill_between(times, data[:,0], data[:,1], color='k') plt.xlim(times[0], times[-1]) plt.xlabel('time (s)') plt.ylabel('amplitude') # You can set the format by changing the extension # like .pdf, .svg, .eps plt.savefig('plot.png', dpi=100) plt.show() |
 |
import numpy as np import scipy.io as sio import scipy.io.wavfile import matplotlib.pyplot as plt import sounddevice as sd # 3-가 samplerate, data = sio.wavfile.read('voice.wav') times = np.arange(len(data))/float(samplerate) sd.play(data, samplerate) plt.fill_between(times, data[:,0], data[:,1], color='k') plt.xlim(times[0], times[-1]) plt.xlabel('time (s)') plt.ylabel('amplitude') plt.show() # 3-나 # Sample rate (샘플레이트) # 이는 샘플의 빈도 수 입니다. # 즉, 1초당 추출되는 샘플 개수라고 할 수 있습니다. # 오디오에서 44.1KHz(44100Hz), 22KHz(22050Hz)를 뜻합니다. # 괄호안에 값은 좀더 정확하게 표현한 값입니다. print( 'sampling rate: ', samplerate) # 3-다 # 따라서 데이터 전체의 개수에서 sample rate를 나누어 주면됩니다. print ('time : ', times[-1]) |
 |
import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
import librosa, librosa.display
fig, axes = plt.subplots(nrows=3, ncols=1)
fig = plt.figure(constrained_layout = True)
samplerate, data = sio.wavfile.read('voice.wav')
duration = len(data)/samplerate
times = np.arange(0,duration,1/samplerate)
# Wave file
plt.subplot(3,1,1)
plt.plot(times,data)
plt.xlabel('time (s)')
plt.ylabel('amplitude')
plt.title('voice.wav')
# FFT (Spectrum)
fft = np.fft.fft(data)
magnitude = np.abs(fft) #abs->manitude
frequency = np.linspace(0,samplerate,len(magnitude))
left_spectrum = magnitude[:int(len(magnitude)/2)]
left_f = frequency[:int(len(magnitude)/2)]
plt.subplot(3,1,2)
plt.plot(left_f, left_spectrum)
plt.xlabel("Frequency")
plt.ylabel("Magnitude")
plt.title("FFT: Power spectrum")
# STFT
audio_path = 'voice.wav'
y, sr = librosa.load(audio_path)
plt.subplot(3,1,3)
stft_result = librosa.stft(y, n_fft=4096, win_length = 4096, hop_length=1024)
D = np.abs(stft_result)
S_dB = librosa.power_to_db(D, ref=np.max)
librosa.display.specshow(S_dB, sr=sr, hop_length = 1024,
y_axis='linear', x_axis='time', cmap = None)
plt.colorbar(format='%2.0f dB')
plt.title("STFT: Power spectrum[dB]")
plt.savefig('voice_wave.png', dpi=100)
#plt.show()
|
출처:
반응형
'성장캐 > 기타' 카테고리의 다른 글
| [에러해결] Jetbot 문제 해결 방법 Jetpack 4.3 4.5 버전 (0) | 2022.04.19 |
|---|---|
| [Python] 하트 그리기 (0) | 2022.04.10 |
| [반도체공학] VHDL로 2 input AND Gate 프로그래밍 (0) | 2022.02.06 |
| 정보통신기술용어해설 사이트 (0) | 2022.02.04 |
| PI WARS (0) | 2022.02.04 |
'성장캐/기타' Related Articles
more



Comments